This document explains the basic communications design and messaging specification for how the various IPython objects interact over a network transport. The current implementation uses the ZeroMQ library for messaging within and between hosts.
Note
This document should be considered the authoritative description of the IPython messaging protocol, and all developers are strongly encouraged to keep it updated as the implementation evolves, so that we have a single common reference for all protocol details.
The basic design is explained in the following diagram:
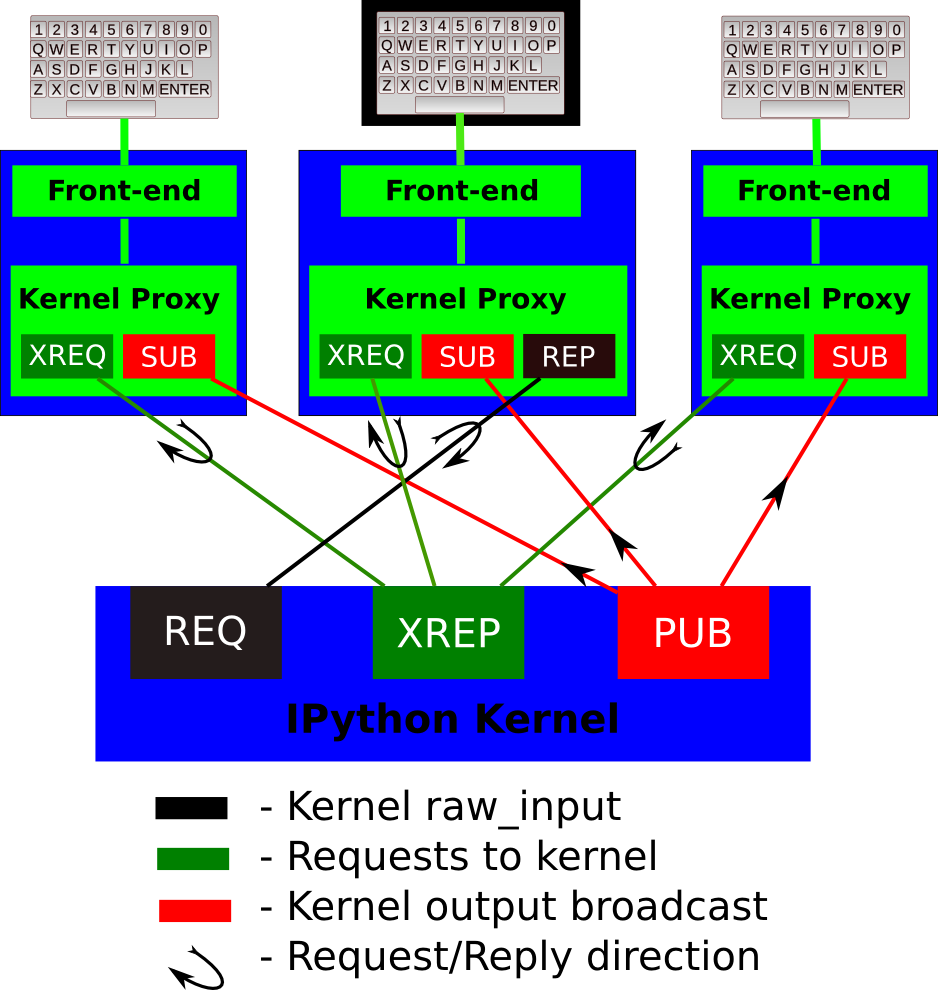
A single kernel can be simultaneously connected to one or more frontends. The kernel has three sockets that serve the following functions:
REQ: this socket is connected to a single frontend at a time, and it allows the kernel to request input from a frontend when raw_input() is called. The frontend holding the matching REP socket acts as a ‘virtual keyboard’ for the kernel while this communication is happening (illustrated in the figure by the black outline around the central keyboard). In practice, frontends may display such kernel requests using a special input widget or otherwise indicating that the user is to type input for the kernel instead of normal commands in the frontend.
XREP: this single sockets allows multiple incoming connections from frontends, and this is the socket where requests for code execution, object information, prompts, etc. are made to the kernel by any frontend. The communication on this socket is a sequence of request/reply actions from each frontend and the kernel.
PUB: this socket is the ‘broadcast channel’ where the kernel publishes all side effects (stdout, stderr, etc.) as well as the requests coming from any client over the XREP socket and its own requests on the REP socket. There are a number of actions in Python which generate side effects: print() writes to sys.stdout, errors generate tracebacks, etc. Additionally, in a multi-client scenario, we want all frontends to be able to know what each other has sent to the kernel (this can be useful in collaborative scenarios, for example). This socket allows both side effects and the information about communications taking place with one client over the XREQ/XREP channel to be made available to all clients in a uniform manner.
All messages are tagged with enough information (details below) for clients to know which messages come from their own interaction with the kernel and which ones are from other clients, so they can display each type appropriately.
The actual format of the messages allowed on each of these channels is specified below. Messages are dicts of dicts with string keys and values that are reasonably representable in JSON. Our current implementation uses JSON explicitly as its message format, but this shouldn’t be considered a permanent feature. As we’ve discovered that JSON has non-trivial performance issues due to excessive copying, we may in the future move to a pure pickle-based raw message format. However, it should be possible to easily convert from the raw objects to JSON, since we may have non-python clients (e.g. a web frontend). As long as it’s easy to make a JSON version of the objects that is a faithful representation of all the data, we can communicate with such clients.
Note
Not all of these have yet been fully fleshed out, but the key ones are, see kernel and frontend files for actual implementation details.
As messages are dicts, they map naturally to a func(**kw) call form. We should develop, at a few key points, functional forms of all the requests that take arguments in this manner and automatically construct the necessary dict for sending.
All messages send or received by any IPython process should have the following generic structure:
{
# The message header contains a pair of unique identifiers for the
# originating session and the actual message id, in addition to the
# username for the process that generated the message. This is useful in
# collaborative settings where multiple users may be interacting with the
# same kernel simultaneously, so that frontends can label the various
# messages in a meaningful way.
'header' : { 'msg_id' : uuid,
'username' : str,
'session' : uuid
},
# In a chain of messages, the header from the parent is copied so that
# clients can track where messages come from.
'parent_header' : dict,
# All recognized message type strings are listed below.
'msg_type' : str,
# The actual content of the message must be a dict, whose structure
# depends on the message type.x
'content' : dict,
}
For each message type, the actual content will differ and all existing message types are specified in what follows of this document.
This message type is used by frontends to ask the kernel to execute code on behalf of the user, in a namespace reserved to the user’s variables (and thus separate from the kernel’s own internal code and variables).
Message type: execute_request:
content = {
# Source code to be executed by the kernel, one or more lines.
'code' : str,
# A boolean flag which, if True, signals the kernel to execute this
# code as quietly as possible. This means that the kernel will compile
# the code witIPython/core/tests/h 'exec' instead of 'single' (so
# sys.displayhook will not fire), and will *not*:
# - broadcast exceptions on the PUB socket
# - do any logging
# - populate any history
#
# The default is False.
'silent' : bool,
# A list of variable names from the user's namespace to be retrieved. What
# returns is a JSON string of the variable's repr(), not a python object.
'user_variables' : list,
# Similarly, a dict mapping names to expressions to be evaluated in the
# user's dict.
'user_expressions' : dict,
}
The code field contains a single string (possibly multiline). The kernel is responsible for splitting this into one or more independent execution blocks and deciding whether to compile these in ‘single’ or ‘exec’ mode (see below for detailed execution semantics).
The user_ fields deserve a detailed explanation. In the past, IPython had the notion of a prompt string that allowed arbitrary code to be evaluated, and this was put to good use by many in creating prompts that displayed system status, path information, and even more esoteric uses like remote instrument status aqcuired over the network. But now that IPython has a clean separation between the kernel and the clients, the kernel has no prompt knowledge; prompts are a frontend-side feature, and it should be even possible for different frontends to display different prompts while interacting with the same kernel.
The kernel now provides the ability to retrieve data from the user’s namespace after the execution of the main code, thanks to two fields in the execute_request message:
With this information, frontends can display any status information they wish in the form that best suits each frontend (a status line, a popup, inline for a terminal, etc).
Note
In order to obtain the current execution counter for the purposes of displaying input prompts, frontends simply make an execution request with an empty code string and silent=True.
When the silent flag is false, the execution of use code consists of the following phases (in silent mode, only the code field is executed):
Warning
The API for running code before/after the main code block is likely to change soon. Both the pre_runcode_hook and the register_post_execute() are susceptible to modification, as we find a consistent model for both.
To understand how the code field is executed, one must know that Python code can be compiled in one of three modes (controlled by the mode argument to the compile() builtin):
Valid for a single interactive statement (though the source can contain multiple lines, such as a for loop). When compiled in this mode, the generated bytecode contains special instructions that trigger the calling of sys.displayhook() for any expression in the block that returns a value. This means that a single statement can actually produce multiple calls to sys.displayhook(), if for example it contains a loop where each iteration computes an unassigned expression would generate 10 calls:
for i in range(10):
i**2
The code field is split into individual blocks each of which is valid for execution in ‘single’ mode, and then:
Any error in retrieving the user_variables or evaluating the user_expressions will result in a simple error message in the return fields of the form:
[ERROR] ExceptionType: Exception message
The user can simply send the same variable name or expression for evaluation to see a regular traceback.
Errors in any registered post_execute functions are also reported similarly, and the failing function is removed from the post_execution set so that it does not continue triggering failures.
Upon completion of the execution request, the kernel always sends a reply, with a status code indicating what happened and additional data depending on the outcome. See below for the possible return codes and associated data.
The kernel has a single, monotonically increasing counter of all execution requests that are made with silent=False. This counter is used to populate the In[n], Out[n] and _n variables, so clients will likely want to display it in some form to the user, which will typically (but not necessarily) be done in the prompts. The value of this counter will be returned as the execution_count field of all execute_reply messages.
Message type: execute_reply:
content = {
# One of: 'ok' OR 'error' OR 'abort'
'status' : str,
# The global kernel counter that increases by one with each non-silent
# executed request. This will typically be used by clients to display
# prompt numbers to the user. If the request was a silent one, this will
# be the current value of the counter in the kernel.
'execution_count' : int,
}
When status is ‘ok’, the following extra fields are present:
{
# The execution payload is a dict with string keys that may have been
# produced by the code being executed. It is retrieved by the kernel at
# the end of the execution and sent back to the front end, which can take
# action on it as needed. See main text for further details.
'payload' : dict,
# Results for the user_variables and user_expressions.
'user_variables' : dict,
'user_expressions' : dict,
# The kernel will often transform the input provided to it. If the
# '---->' transform had been applied, this is filled, otherwise it's the
# empty string. So transformations like magics don't appear here, only
# autocall ones.
'transformed_code' : str,
}
Execution payloads
The notion of an ‘execution payload’ is different from a return value of a given set of code, which normally is just displayed on the pyout stream through the PUB socket. The idea of a payload is to allow special types of code, typically magics, to populate a data container in the IPython kernel that will be shipped back to the caller via this channel. The kernel will have an API for this, probably something along the lines of:
ip.exec_payload_add(key, value)
though this API is still in the design stages. The data returned in this payload will allow frontends to present special views of what just happened.
When status is ‘error’, the following extra fields are present:
{
'exc_name' : str, # Exception name, as a string
'exc_value' : str, # Exception value, as a string
# The traceback will contain a list of frames, represented each as a
# string. For now we'll stick to the existing design of ultraTB, which
# controls exception level of detail statefully. But eventually we'll
# want to grow into a model where more information is collected and
# packed into the traceback object, with clients deciding how little or
# how much of it to unpack. But for now, let's start with a simple list
# of strings, since that requires only minimal changes to ultratb as
# written.
'traceback' : list,
}
When status is ‘abort’, there are for now no additional data fields. This happens when the kernel was interrupted by a signal.
Warning
This part of the messaging spec is not actually implemented in the kernel yet.
While this protocol does not specify full RPC access to arbitrary methods of the kernel object, the kernel does allow read (and in some cases write) access to certain attributes.
The policy for which attributes can be read is: any attribute of the kernel, or its sub-objects, that belongs to a Configurable object and has been declared at the class-level with Traits validation, is in principle accessible as long as its name does not begin with a leading underscore. The attribute itself will have metadata indicating whether it allows remote read and/or write access. The message spec follows for attribute read and write requests.
Message type: getattr_request:
content = {
# The (possibly dotted) name of the attribute
'name' : str,
}
When a getattr_request fails, there are two possible error types:
Message type: getattr_reply:
content = {
# One of ['ok', 'AttributeError', 'AccessError'].
'status' : str,
# If status is 'ok', a JSON object.
'value' : object,
}
Message type: setattr_request:
content = {
# The (possibly dotted) name of the attribute
'name' : str,
# A JSON-encoded object, that will be validated by the Traits
# information in the kernel
'value' : object,
}
When a setattr_request fails, there are also two possible error types with similar meanings as those of the getattr_request case, but for writing.
Message type: setattr_reply:
content = {
# One of ['ok', 'AttributeError', 'AccessError'].
'status' : str,
}
One of IPython’s most used capabilities is the introspection of Python objects in the user’s namespace, typically invoked via the ? and ?? characters (which in reality are shorthands for the %pinfo magic). This is used often enough that it warrants an explicit message type, especially because frontends may want to get object information in response to user keystrokes (like Tab or F1) besides from the user explicitly typing code like x??.
Message type: object_info_request:
content = {
# The (possibly dotted) name of the object to be searched in all
# relevant namespaces
'name' : str,
# The level of detail desired. The default (0) is equivalent to typing
# 'x?' at the prompt, 1 is equivalent to 'x??'.
'detail_level' : int,
}
The returned information will be a dictionary with keys very similar to the field names that IPython prints at the terminal.
Message type: object_info_reply:
content = {
# The name the object was requested under
'name' : str,
# Boolean flag indicating whether the named object was found or not. If
# it's false, all other fields will be empty.
'found' : bool,
# Flags for magics and system aliases
'ismagic' : bool,
'isalias' : bool,
# The name of the namespace where the object was found ('builtin',
# 'magics', 'alias', 'interactive', etc.)
'namespace' : str,
# The type name will be type.__name__ for normal Python objects, but it
# can also be a string like 'Magic function' or 'System alias'
'type_name' : str,
# The string form of the object, possibly truncated for length if
# detail_level is 0
'string_form' : str,
# For objects with a __class__ attribute this will be set
'base_class' : str,
# For objects with a __len__ attribute this will be set
'length' : int,
# If the object is a function, class or method whose file we can find,
# we give its full path
'file' : str,
# For pure Python callable objects, we can reconstruct the object
# definition line which provides its call signature. For convenience this
# is returned as a single 'definition' field, but below the raw parts that
# compose it are also returned as the argspec field.
'definition' : str,
# The individual parts that together form the definition string. Clients
# with rich display capabilities may use this to provide a richer and more
# precise representation of the definition line (e.g. by highlighting
# arguments based on the user's cursor position). For non-callable
# objects, this field is empty.
'argspec' : { # The names of all the arguments
args : list,
# The name of the varargs (*args), if any
varargs : str,
# The name of the varkw (**kw), if any
varkw : str,
# The values (as strings) of all default arguments. Note
# that these must be matched *in reverse* with the 'args'
# list above, since the first positional args have no default
# value at all.
defaults : list,
},
# For instances, provide the constructor signature (the definition of
# the __init__ method):
'init_definition' : str,
# Docstrings: for any object (function, method, module, package) with a
# docstring, we show it. But in addition, we may provide additional
# docstrings. For example, for instances we will show the constructor
# and class docstrings as well, if available.
'docstring' : str,
# For instances, provide the constructor and class docstrings
'init_docstring' : str,
'class_docstring' : str,
# If it's a callable object whose call method has a separate docstring and
# definition line:
'call_def' : str,
'call_docstring' : str,
# If detail_level was 1, we also try to find the source code that
# defines the object, if possible. The string 'None' will indicate
# that no source was found.
'source' : str,
}
‘
Message type: complete_request:
content = {
# The text to be completed, such as 'a.is'
'text' : str,
# The full line, such as 'print a.is'. This allows completers to
# make decisions that may require information about more than just the
# current word.
'line' : str,
# The entire block of text where the line is. This may be useful in the
# case of multiline completions where more context may be needed. Note: if
# in practice this field proves unnecessary, remove it to lighten the
# messages.
'block' : str,
# The position of the cursor where the user hit 'TAB' on the line.
'cursor_pos' : int,
}
Message type: complete_reply:
content = {
# The list of all matches to the completion request, such as
# ['a.isalnum', 'a.isalpha'] for the above example.
'matches' : list
}
For clients to explicitly request history from a kernel. The kernel has all the actual execution history stored in a single location, so clients can request it from the kernel when needed.
Message type: history_request:
content = {
# If True, also return output history in the resulting dict.
'output' : bool,
# If True, return the raw input history, else the transformed input.
'raw' : bool,
# So far, this can be 'range', 'tail' or 'search'.
'hist_access_type' : str,
# If hist_access_type is 'range', get a range of input cells. session can
# be a positive session number, or a negative number to count back from
# the current session.
'session' : int,
# start and stop are line numbers within that session.
'start' : int,
'stop' : int,
# If hist_access_type is 'tail', get the last n cells.
'n' : int,
# If hist_access_type is 'search', get cells matching the specified glob
# pattern (with * and ? as wildcards).
'pattern' : str,
}
Message type: history_reply:
content = {
# A list of 3 tuples, either:
# (session, line_number, input) or
# (session, line_number, (input, output)),
# depending on whether output was False or True, respectively.
'history' : list,
}
When a client connects to the request/reply socket of the kernel, it can issue a connect request to get basic information about the kernel, such as the ports the other ZeroMQ sockets are listening on. This allows clients to only have to know about a single port (the XREQ/XREP channel) to connect to a kernel.
Message type: connect_request:
content = {
}
Message type: connect_reply:
content = {
'xrep_port' : int # The port the XREP socket is listening on.
'pub_port' : int # The port the PUB socket is listening on.
'req_port' : int # The port the REQ socket is listening on.
'hb_port' : int # The port the heartbeat socket is listening on.
}
The clients can request the kernel to shut itself down; this is used in multiple cases:
The client sends a shutdown request to the kernel, and once it receives the reply message (which is otherwise empty), it can assume that the kernel has completed shutdown safely.
Upon their own shutdown, client applications will typically execute a last minute sanity check and forcefully terminate any kernel that is still alive, to avoid leaving stray processes in the user’s machine.
For both shutdown request and reply, there is no actual content that needs to be sent, so the content dict is empty.
Message type: shutdown_request:
content = {
'restart' : bool # whether the shutdown is final, or precedes a restart
}
Message type: shutdown_reply:
content = {
'restart' : bool # whether the shutdown is final, or precedes a restart
}
Note
When the clients detect a dead kernel thanks to inactivity on the heartbeat socket, they simply send a forceful process termination signal, since a dead process is unlikely to respond in any useful way to messages.
Message type: stream:
content = {
# The name of the stream is one of 'stdin', 'stdout', 'stderr'
'name' : str,
# The data is an arbitrary string to be written to that stream
'data' : str,
}
When a kernel receives a raw_input call, it should also broadcast it on the pub socket with the names ‘stdin’ and ‘stdin_reply’. This will allow other clients to monitor/display kernel interactions and possibly replay them to their user or otherwise expose them.
This type of message is used to bring back data that should be diplayed (text, html, svg, etc.) in the frontends. This data is published to all frontends. Each message can have multiple representations of the data; it is up to the frontend to decide which to use and how. A single message should contain all possible representations of the same information. Each representation should be a JSON’able data structure, and should be a valid MIME type.
Some questions remain about this design:
Message type: display_data:
content = {
# Who create the data
'source' : str,
# The data dict contains key/value pairs, where the kids are MIME
# types and the values are the raw data of the representation in that
# format. The data dict must minimally contain the ``text/plain``
# MIME type which is used as a backup representation.
'data' : dict,
# Any metadata that describes the data
'metadata' : dict
}
These messages are the re-broadcast of the execute_request.
Message type: pyin:
content = {
'code' : str # Source code to be executed, one or more lines
}
When Python produces output from code that has been compiled in with the ‘single’ flag to compile(), any expression that produces a value (such as 1+1) is passed to sys.displayhook, which is a callable that can do with this value whatever it wants. The default behavior of sys.displayhook in the Python interactive prompt is to print to sys.stdout the repr() of the value as long as it is not None (which isn’t printed at all). In our case, the kernel instantiates as sys.displayhook an object which has similar behavior, but which instead of printing to stdout, broadcasts these values as pyout messages for clients to display appropriately.
IPython’s displayhook can handle multiple simultaneous formats depending on its configuration. The default pretty-printed repr text is always given with the data entry in this message. Any other formats are provided in the extra_formats list. Frontends are free to display any or all of these according to its capabilities. extra_formats list contains 3-tuples of an ID string, a type string, and the data. The ID is unique to the formatter implementation that created the data. Frontends will typically ignore the ID unless if it has requested a particular formatter. The type string tells the frontend how to interpret the data. It is often, but not always a MIME type. Frontends should ignore types that it does not understand. The data itself is any JSON object and depends on the format. It is often, but not always a string.
Message type: pyout:
content = {
# The counter for this execution is also provided so that clients can
# display it, since IPython automatically creates variables called _N
# (for prompt N).
'execution_count' : int,
# The data dict contains key/value pairs, where the kids are MIME
# types and the values are the raw data of the representation in that
# format. The data dict must minimally contain the ``text/plain``
# MIME type which is used as a backup representation.
'data' : dict,
}
When an error occurs during code execution
Message type: pyerr:
content = {
# Similar content to the execute_reply messages for the 'error' case,
# except the 'status' field is omitted.
}
This message type is used by frontends to monitor the status of the kernel.
Message type: status:
content = {
# When the kernel starts to execute code, it will enter the 'busy'
# state and when it finishes, it will enter the 'idle' state.
execution_state : ('busy', 'idle')
}
When the kernel has an unexpected exception, caught by the last-resort sys.excepthook, we should broadcast the crash handler’s output before exiting. This will allow clients to notice that a kernel died, inform the user and propose further actions.
Message type: crash:
content = {
# Similarly to the 'error' case for execute_reply messages, this will
# contain exc_name, exc_type and traceback fields.
# An additional field with supplementary information such as where to
# send the crash message
'info' : str,
}
Other potential message types, currently unimplemented, listed below as ideas.
Message type: file:
content = {
'path' : 'cool.jpg',
'mimetype' : str,
'data' : str,
}
This is a socket that goes in the opposite direction: from the kernel to a single frontend, and its purpose is to allow raw_input and similar operations that read from sys.stdin on the kernel to be fulfilled by the client. For now we will keep these messages as simple as possible, since they basically only mean to convey the raw_input(prompt) call.
Message type: input_request:
content = { 'prompt' : str }
Message type: input_reply:
content = { 'value' : str }
Note
We do not explicitly try to forward the raw sys.stdin object, because in practice the kernel should behave like an interactive program. When a program is opened on the console, the keyboard effectively takes over the stdin file descriptor, and it can’t be used for raw reading anymore. Since the IPython kernel effectively behaves like a console program (albeit one whose “keyboard” is actually living in a separate process and transported over the zmq connection), raw stdin isn’t expected to be available.
Initially we had considered using messages like those above over ZMQ for a kernel ‘heartbeat’ (a way to detect quickly and reliably whether a kernel is alive at all, even if it may be busy executing user code). But this has the problem that if the kernel is locked inside extension code, it wouldn’t execute the python heartbeat code. But it turns out that we can implement a basic heartbeat with pure ZMQ, without using any Python messaging at all.
The monitor sends out a single zmq message (right now, it is a str of the monitor’s lifetime in seconds), and gets the same message right back, prefixed with the zmq identity of the XREQ socket in the heartbeat process. This can be a uuid, or even a full message, but there doesn’t seem to be a need for packing up a message when the sender and receiver are the exact same Python object.
The model is this:
monitor.send(str(self.lifetime)) # '1.2345678910'
and the monitor receives some number of messages of the form:
['uuid-abcd-dead-beef', '1.2345678910']
where the first part is the zmq.IDENTITY of the heart’s XREQ on the engine, and the rest is the message sent by the monitor. No Python code ever has any access to the message between the monitor’s send, and the monitor’s recv.
Missing things include: